Machine Learning Definitions¶
Arthur Samuel (Coined the term in 1959 at IBM):
“A field of Computer Science that gives computers the ability to learn without being explicitly programmed.”
Deep Learning, Goodfellow et al:
“The ability [for systems] to acquire their own knowledge, by extracting patterns from raw data.”
Tom Mitchell (Computer Scientist & Professor at Carnegie Mellon):
“A computer program is said to learn from experience E with respect to some set of tasks T and performance measure P if its performance tasks in T, as measured by P, improves with experience E.”
Machine Learning Overview¶
A general-purpose technology or GPT is a term coined to describe a new method of producing and inventing that is important enough to have a protracted aggregate impact. Means that ML can be used across all market sectors everything from Marketing to Agriculture to Sports.
However, there is a lot of confusion about what is meant by Machine Learning, especially with all the buzz around Artificial Intelligence.
I always found the graphic below really helpful in explaining the difference between AI and Machine Learning. Essentially Machine Learning is a subcategory of AI and Deep Learning is a type of Machine Learning. In the current popular culture discourse when people say “AI” what they really mean is Deep Learning. Which is a type of Machine Learning that focuses on the use of Neural Networks.
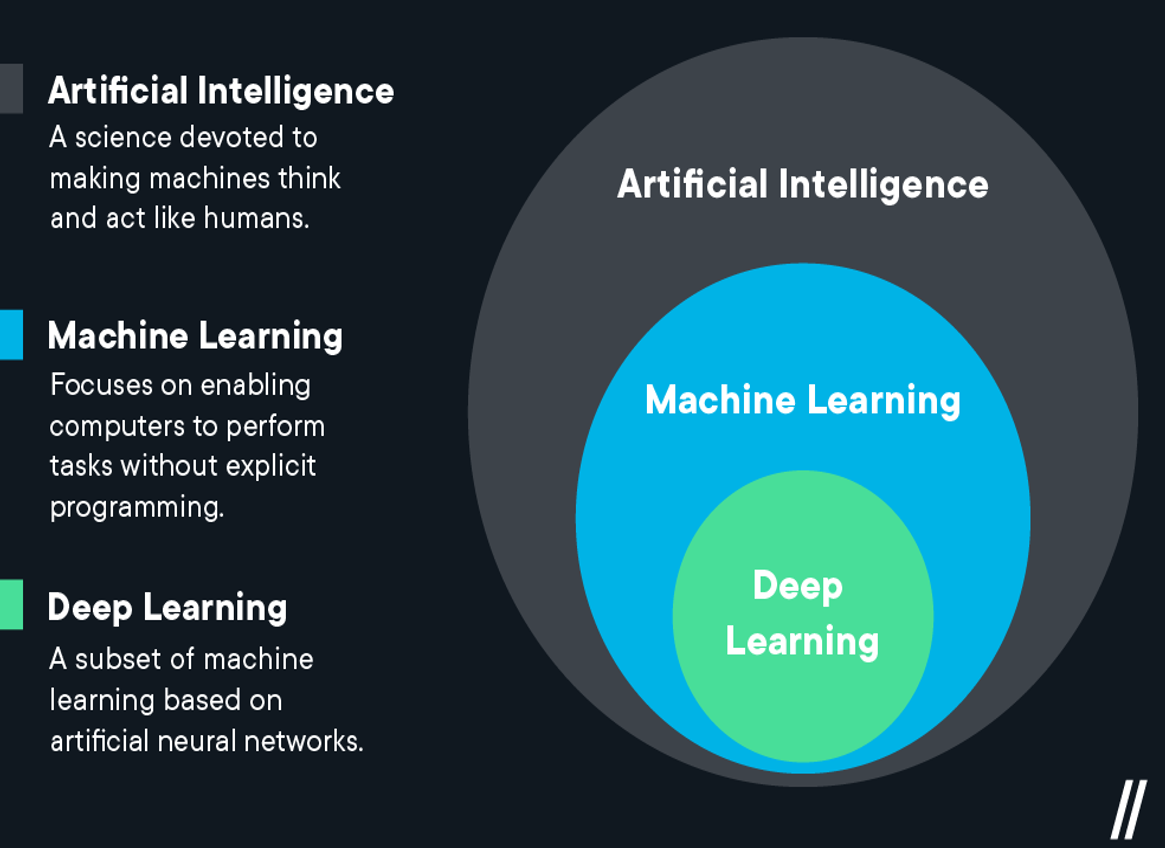
.
Types of Machine Learning¶
Supervised Machine Learning¶
When we know what is to be learned by the machine, we have a target variable. In cases of classification this is a discrete number and often is binary [1,0]. Regression is the other situation, meaning that our target variable is continuous. An example of a discrete target might be whether a student gets admitted into college or not, as compared to a continuous that might try to predict the total points scored in a basketball game.
Another way to think about it is that we understand the end point of the problem but have not yet discovered the road to get there. As an example, think of a online social media platform with the goal of ensuring you stay on the platform as long as possible so you can see more ads, which drives up revenue for the site. The goal is to build a machine that can predict which content will keep you on the site as long as possible and then serve that content as fast as possible.
Consider this example and use the definitions below to identify in this scenario what is the target, possible features and the business metric.
Model Definitions¶
Target Variable: This is the variable we are interested in better understanding.
Features: These are the variables we will use to better understand the target variable.
Independent Business Metric: The measure we use to track whether the algorithm we have built is delivering value for our organization.
Answers (don’t look until you’ve finished)
Target: Amount of time users spend on the site
Features: Clicks, demographics of the customers, time of day, web browser, browsing history, type of content..etc.
Metric: Revenue generated after the model is deployed.
Unsupervised Machine Learning¶
When we do not know what is to be learned by the machine or more simply we do not have a target variable. Another way to think about it is that we do not know the end point or the road!
Let’s use same example from above of a online social media platform with the goal to ensure you stay on the platform as long as possible. We have the same problem, trying to predict which content will keep you on the site as long as possible and then serving content as fast as possible. Consider this example but instead of defining the items, instead try to think of a portion of the problem that would require a unsupervised approach.
Answer (don’t look until you’ve finished)
A common use for unsupervised machine learning in e-commerce is customers segmentation. We essentially divided the customers into groups based on buying patterns and associated features. The key point here is that we do not know what the groups are before we begin the process, thus the unsupervised learning.
Reinforcement Learning¶
The last general category is reinforcement learning which you can think of a combination of the two previous categories. Reinforcement methods do not need to have labelled data, meaning input-output pairs are not needed. Instead these algos use knowledge that is present to adopt to the environment. To use the driving example, we know where we are going but as compared to supervised learning that determines the best way to get there ahead of time, instead we simply start driving to learn the fastest way.
Another example is how animals adopt to their environments in such a way that maximizes food and reduces danger. This course will mostly focus on supervised methods with some unsupervised.
Machine Learning Ready¶
Successful implementation of machine learning algorithms requires detailed planning and clear requirements on what is to be learned. In large part this requires a lot of trail and error and a robust engineering process to ensure the solution can and does work in deployment. This is why we will focus a lot on the Data Science Lifecycle, throughout the course and work to employ a Experimental Mindset that is critical for successfully development any ML algo.
Ideal Conditions..Suitable for Machine Learning¶
Large Datasets: Now what large means is dependant on the situation trying to be learned, but generally small datasets with a few hundred rows just do not work well with ML algorithms.
Inputs Need to Map Well to Outputs: This is true of all quantitative modelling and it seems simple, but not all dataset are high quality enough to be used for prediction. This is possibly the most important lesson to learn. The data science lifecycle (next section) is less about building a algorithms and more about proving the data you have can address the problem at hand.
Causality is Not Required: The approaches we will cover in this course and most machine learning approaches, do not address causality. This is a key difference between classical statistics that works to model some behavior or process as compared to machine learning that only looks to generate predictive probabilities. Put more plainly, machine learning algorithms should not be used when you need to know why the results are occurring. This means we cannot say the features we are using in our algorithms are causing the target only that they are predictive of the target.