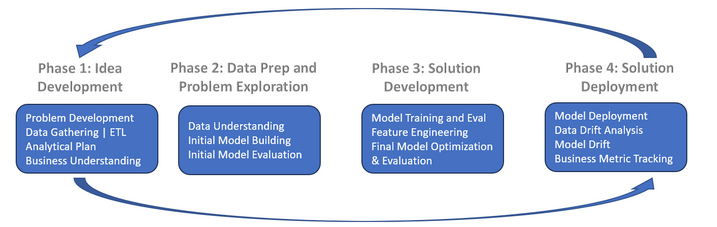
The Data Science Lifecycle as seen below is critical to understand when getting started with exploring Machine Learning algorithms. There are likely hundreds of versions of this lifecycle but we will be using the one below throughout this class. As you can see it broken down into four high level phases: Idea Development, Data Preparation and Problem Exploration, Solution Development and Model Development.
Idea Development¶
Idea development includes four steps and is likely the most important part of the entire lifecycle. It is critical to fully understand the problem you are trying to solve and to at a minimum develop a outline for how the analytics process will proceed. It is common to complete this phase with a analytical plan that can be present to stakeholders and agreed upon by your team. This should include the follow four high components.
Analytical Plan:
A detailed explanation of the problem you are working to solve.
Understanding the business problem.
Defining the scope of the project (what to do and more importantly not to do).
Identifying the target variable for supervised or goal for unsupervised.
Data Knowledge
How much data do you have and does it match the problem?
Where did the data come from and are there any biases or issues (too old, missing, duplicates, etc.)?
How has the data been used previously, if at all?
Does it change rapidly?
Identification of Algorithmic Approach
Which methods are you going to explore and why?
Should include identification of evaluation measures.
If possible benchmarks for impact should be established, how good does the algo need to work.
Identification of a Independent Business Metric
Separate metric not aligned with the performance of the algorithm that allows your organization to know if implementation of the machine learning approach is working.
Phase 1: Idea Development¶
Question ID - This could be a piece of a larger problem, actually it almost certainly is a piece of a larger problem. Be specific as possible.
Business Understanding - This might require additional team members or lots of conversations to make sure you and your team our working on a project that is aligned with the organizations goals. Remember data scientist are present to create valuable information for themselves or their organizations, knowing the best way to do that is critical!
Evaluation Criteria - How the algorithm will be measured and any a projected benchmark that needs to be met.
Data Acquisition|ETL - Find data to match the problem and begin to evaluate the effectiveness. There’s literally books written on just this step, but major sources of information include: online databases, internal company data, APIs, webscraping and even using real-time senors. Jon Kropko a fellow faculty member at the School of Data Science has a really nice overview on how to access data from various sources. Please check it out here: Jon Kropko’s Awesome Surfing the Data Pipeline Book.
Phase II: Data Preparation and Problem Exploration¶
Data Understanding + Exploratory Data Analysis - This is step where we really dig into the data that we have to try to better the potential and pitfalls of the information we have and how well it might fit our problem. This is where we try to fix issues to get the information ready for machine learning approaches. The good news is, we have lots of great tools to support this step. The bad news is, it usually takes the most time out of all the steps in the lifecycle.
Initial Model Building - This is the step where you start to get an idea of how your project is going to go. The goal is build a simple model to determine how well the data matches the problem. Usually this process includes the use of simple algorithmic approaches and possible use a sample of the data available to save on computation time and cost.
Initial Model Building - This step could be assumed to be apart of step 2, but the reason it is separated is that we should be utilizing the metric we identified in phase 1. In doing so the creation of a fairly robust understanding of the potential or issues with the project should be identified.
Phase III: Solution Development¶
Model Training and Testing - In this third phase we have a general idea of how well our data fits the problem through the development of a initial model. We now move forward with either continuing to tune this initial model or purposely choose additional algorithmic techniques to explore. This should not be a “try everything and see what sticks” approach, but instead a thoughtful decision on which approaches to try based on your data.
Feature Engineering is a crucial step in the machine learning process that involves creating new features or modifying existing ones to improve the performance of a model. It is inherently a experimental process and should be treating accordingly. Effective feature engineering can significantly enhance the predictive power of a model by providing it with more relevant and informative inputs, but it could make the model worse! Careful documentation of the choices you are making along the way are as a result critical. This process often requires domain knowledge and creativity to identify the most impactful features.
Algorithm Tuning also known as hyperparameter tuning, is the process of optimizing the parameters that govern the behavior of a machine learning algorithm to improve its performance. Unlike model parameters (features), which are learned from the training data, hyperparameters are set before the training process begins and control aspects such as learning rate, regularization strength, the number of trees in random forest, or the number of layers in a neural network, etc. Effective tuning involves systematically searching through a range of hyperparameter values using techniques like grid search, random search, or more advanced methods such as Bayesian optimization. The goal is to find the combination of hyperparameters that yields the best performance on a validation set, thereby enhancing the model’s ability to generalize to unseen data. Proper algorithm tuning can significantly boost the accuracy and efficiency of machine learning models, making it a critical step in the model development lifecycle.
Evaluation - is the process of assessing the performance of a trained model to determine its effectiveness and reliability in making predictions. This involves using various metrics and techniques to measure how well the model performs on a separate validation or test dataset that was not used during training. Common evaluation metrics include accuracy, precision, recall, F1 score, and area under the ROC curve (AUC), each providing different insights into the model’s performance. Evaluation helps identify issues such as overfitting, where the model performs well on training data but poorly on unseen data, and underfitting, where the model fails to capture the underlying patterns in the data. By thoroughly evaluating a model, you can make informed decisions about model selection, tuning, and deployment, to help the model perform better in real-world scenarios.
Phase IV: Solution Deployment (ML Engineering)¶
Solution Deployment can be the one of hardest parts of the entire lifecycle. Typically this involves creating test scenarios that track the effectiveness of the algorithm in real-time and can require adoptive measures to ensure solutions are working correctly. This is when software engineers and data scientists work hand and hand.
Algorithm deployment - When we have constructed our data pipeline and computation environment to allow for the model to go live. This might be in a testing environment (A/B Testing) or not.
Data Model and Data Drift Analysis - stated plainly, no ML solution last forever, the truth is data changes over time, often rapidly and data scientist need to track these changes in order to ensure solutions stay reliable.